
Ahoy!
I design AI-driven experiences that simplify complex workflows and deliver measurable impact. With 16+ years at startups and global enterprises including Tealium, Cypress.io, CallRail, CNN, and MTV Networks, I combine visual craft, systems thinking, and data-driven design to create scalable, high-impact solutions.

The Design
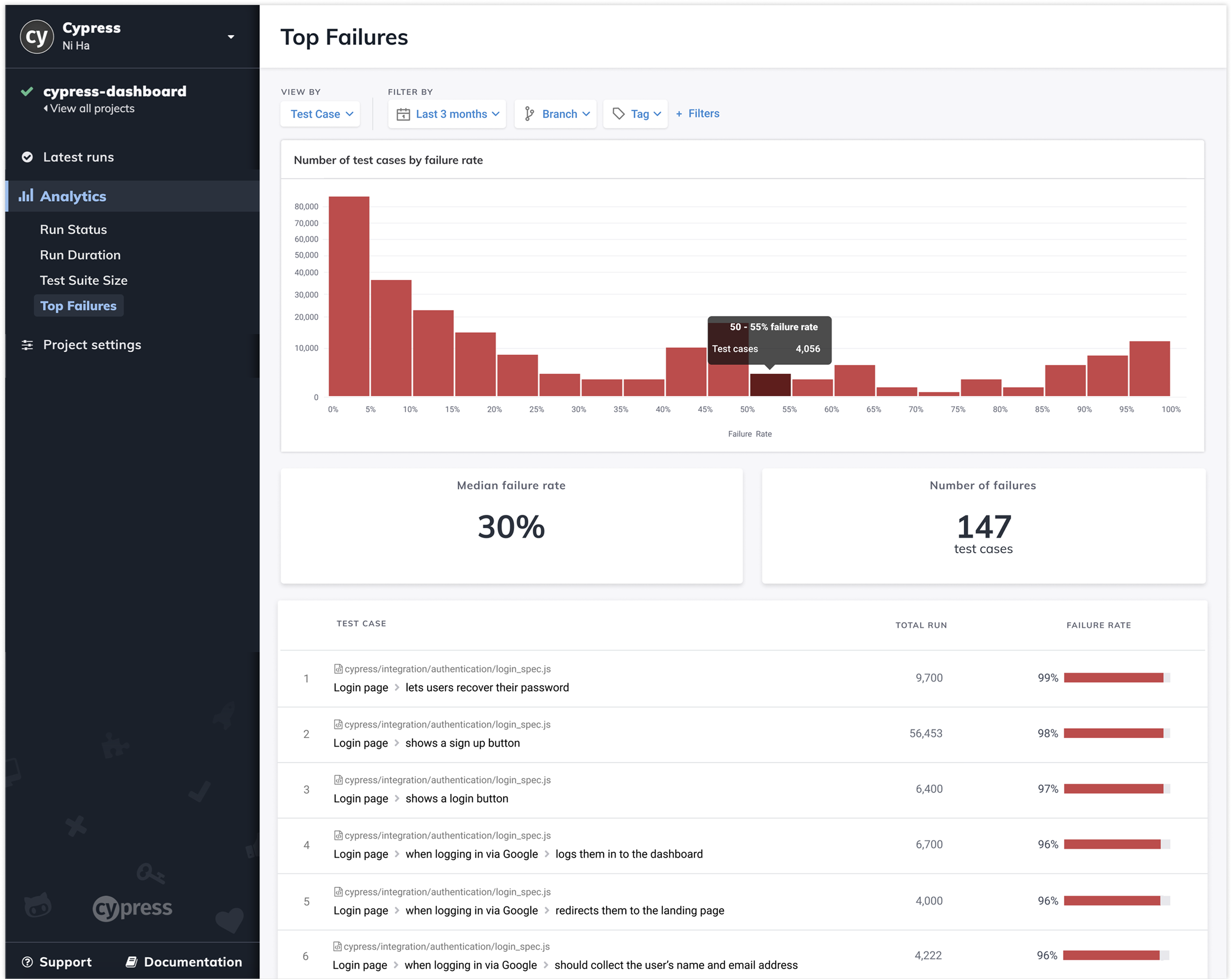
1. Make Test Case Debugging First-Class
Clear failure summary, stack traces, run history
Reduced clutter, surfaced actionable context
Shifts experience from “view results” → “understand & fix”
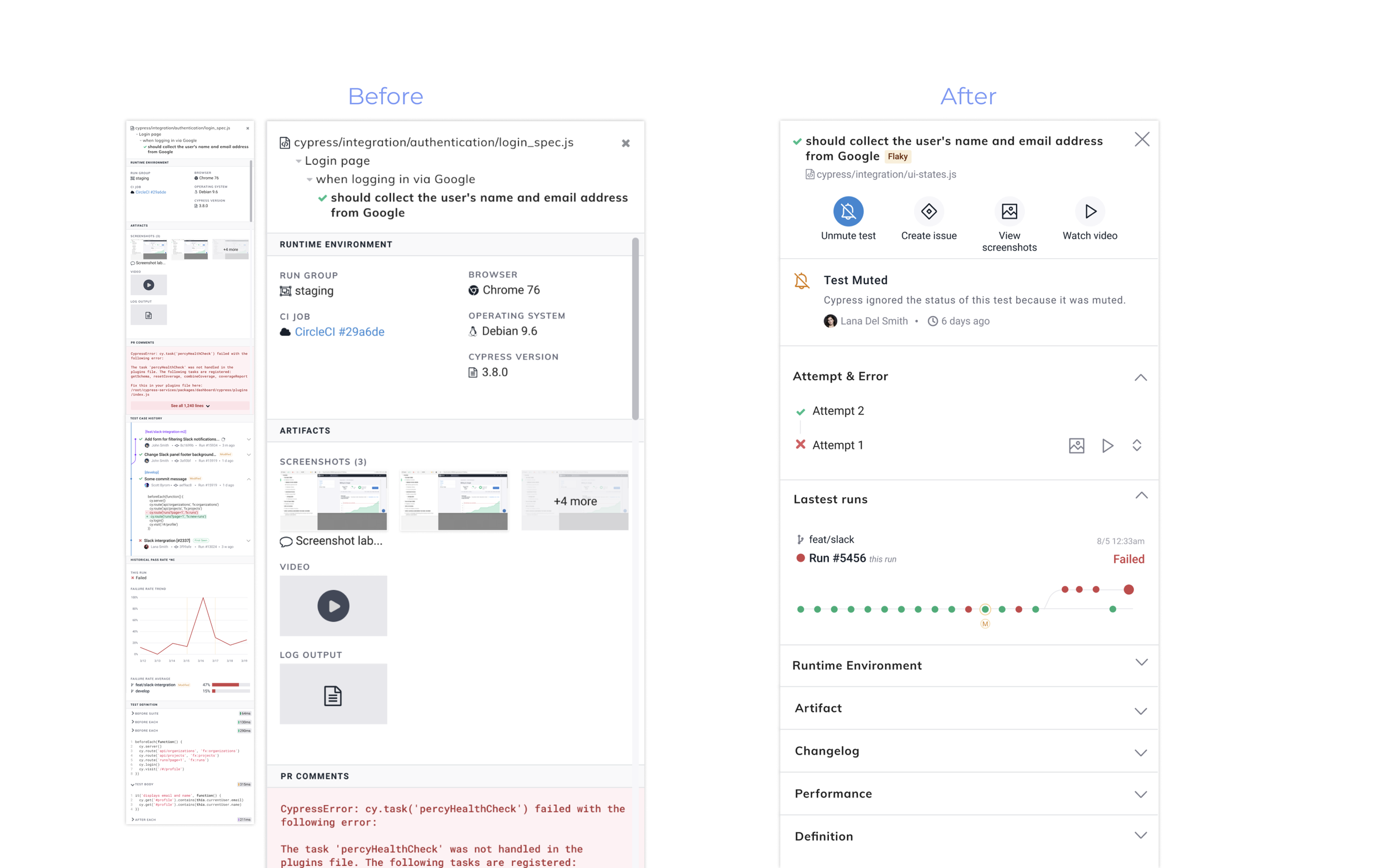
Optimized for diagnosis, not reporting
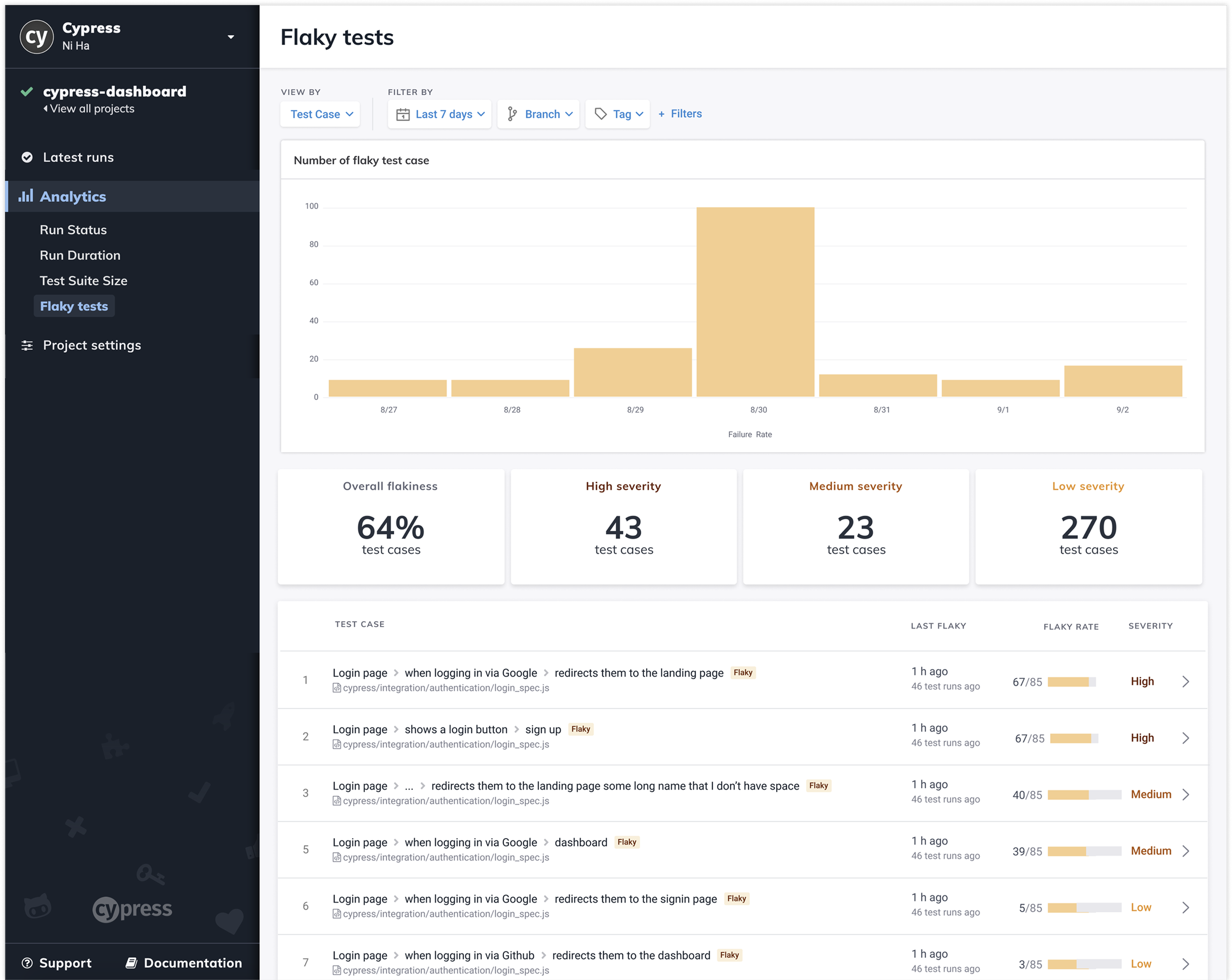
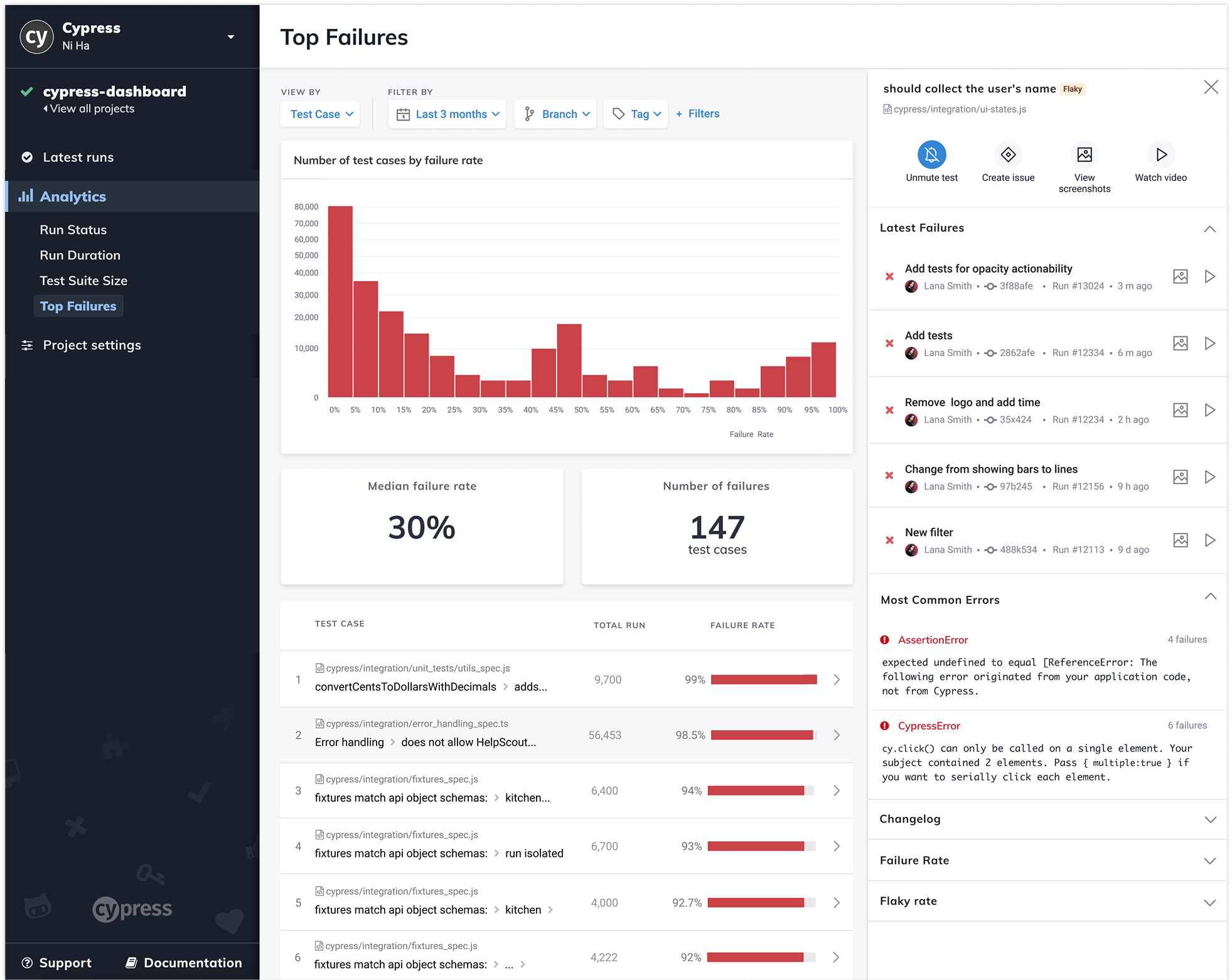
2. Identify Unreliable (Flaky) Tests
Reliability indicator at test level
Failure frequency across runs
Separates intermittent vs consistent failures
3. Aggregate Errors to Reveal Systemic Issues
Grouped errors by type and frequency
Ranked by impact
Drill-down to affected tests
Focus teams on root causes, not individual failures
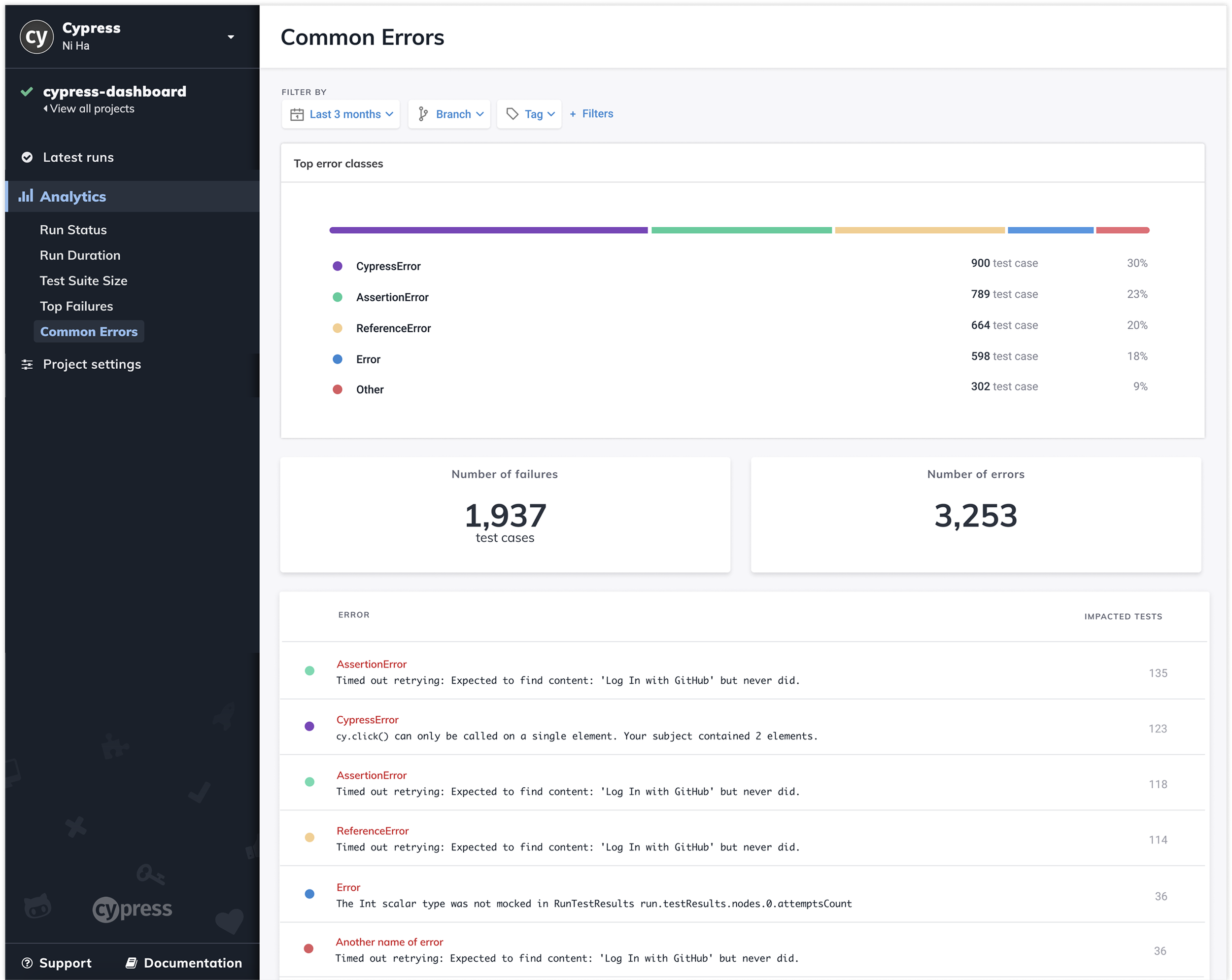
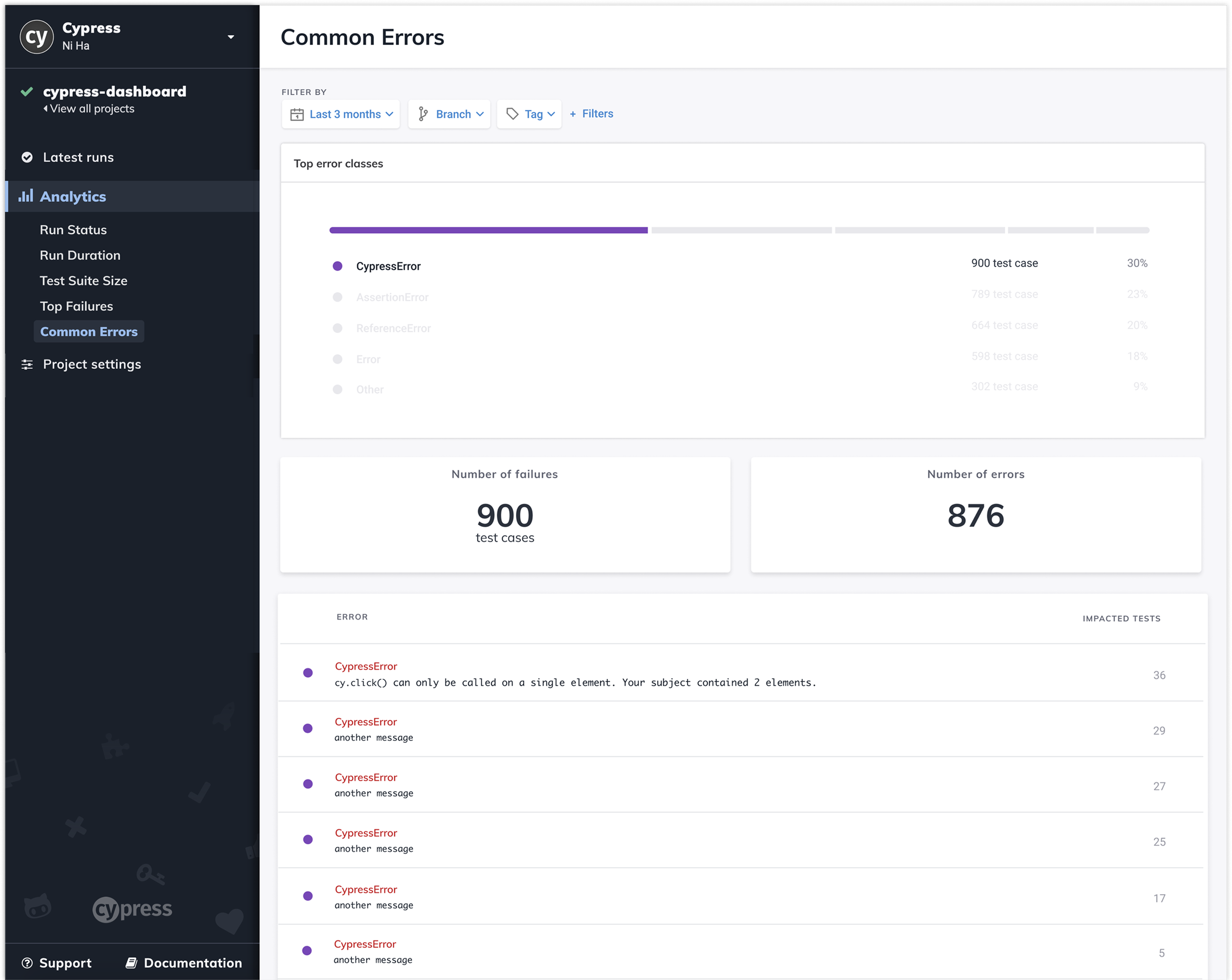
4. Reduce Visual Noise & Improve Scanability
Removed low-value metadata
Improved hierarchy and spacing
Highlighted actionable details
UI feels faster, purpose-driven, usable at scale

Removed noise, elevated signal.
Impact
Platform Impact
Faster investigation: Identify & fix flaky tests ~70% quicker
Prioritized fixes: Focus on failures that block merges or affect most tests
Critical workflow tool: From reporting → actionable diagnosis
UX NPS: +75 developer satisfaction score (high likelihood to recommend; notable adopters include Pendo, Gusto, and Productboard)
Business Impact
Subscription upgrades: ~15% of teams on the free plan upgraded to paid to access Test Analytics
Revenue uplift: Paid tier adoption contributed to a 16 % increase in quarterly ARR after launch
Developer velocity: Faster debugging reduced cycle time, supporting quicker releases
Retention boost: Higher usage and confidence in Cloud features correlated with improved customer retention
What I Would Do Differently
Add trend views to track reliability over time
Enable ownership workflows (assign flaky tests / error groups)
Prioritize failures that block merges most often
Move from diagnosis → full reliability management